fabric 으로 원격 호스트에서 접속하고 로그를 가져올 때 연결되어 있는 호스트가 복잡하고 로그 path 로 여러개가 존재하면
단일 함수로 작성하는 것이 힘들고 함수 자체고 너무 커지고 복잡해져서 디버깅이 힘듭니다.
그리고 로그를 가져온 후에 로그를 원하는 파트로 분해하는 parsing 과정이 필요합니다.
즉, 호스트가 매우 많고 path 도 여러개이고 parsing 도 복잡한 과정이 필요하면 각각에 많는 모듈로 분해를 할 필요가 있습니다.
호스트 몇개 없을 때는 문제가 발생하지 않지만 호스트가 매우 많다면 각각을 담담할 모듈로 분해를 해야합니다.
| 모듈 | 설명 |
| SshManager | ssh connection 연결을 담당 |
| LogSearchScheduler | 로그 검색을 Step 별로 나누어 각 Step 별 검색 스케줄링을 담당 |
| LogParser | 로그 파싱을 담당 |
| LogSearchManager | 그 검색의 메인 역할을 담당하고 각 모듈을 통합 |
1) SshManager
Python의 Fabric은 SSH 연결을 기반으로 동작합니다.
Fabric은 원격 서버에 SSH로 접속해서 명령을 실행하거나 파일을 업로드/다운로드하는 작업을 간편하게 자동화할 수 있는 라이브러리입니다. 주로 배포 자동화나 서버 관리 등의 작업에 많이 사용됩니다.
핵심은 paramiko를 사용해 SSH 연결을 시도하는 것이며, 맞는 비밀번호를 찾으면 해당 정보를 반환합니다.
아래 코드는 git 을 통해 다운받을 수 있습니다.
git clone git@github.com:jbpark/jbDeskExample.git
cd jbDeskExample/jbDesk/ch3.3
ssh_util.py
import logging
import paramiko
from lib.util.encoding_util import decrypt_cipher_text
# logging.basicConfig(level=logging.DEBUG)
def get_ssh_user_info(ssh_user_infos, host_ip, first_index, check_sudo=True):
attempts = 0 # Counter for keeping track of attempts
sorted_infos = sorted(ssh_user_infos, key=lambda x: (x.index != first_index, x.index))
for ssh_connect_info in sorted_infos:
user_name = ssh_connect_info.user_name
password = decrypt_cipher_text(ssh_connect_info.password)
print(f"Attempting attempts:{attempts}, index:{ssh_connect_info.index}")
client = paramiko.SSHClient()
client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
try:
client.connect(host_ip, username=user_name, password=password, timeout=2)
print(f"[>] Valid password found index:{ssh_connect_info.index}")
client.close()
return ssh_connect_info
except paramiko.AuthenticationException:
print("Invalid password!")
except Exception as e:
print(f"Connection failed: {e}")
finally:
client.close()
attempts += 1 # Increment the attempts counter for each password
return None
🔍 주요 기능 요약
- ssh_user_infos: 여러 개의 SSH 사용자 정보를 가진 객체 리스트 (아마 사용자명, 암호화된 비밀번호, 우선순위 index 포함).
- host_ip: 접속하려는 원격 서버의 IP 주소.
- first_index: 우선적으로 시도할 계정 index.
- decrypt_cipher_text: 암호화된 비밀번호를 복호화하는 함수.
✅ 동작 흐름
- first_index 기준으로 우선순위를 두어 정렬 (first_index를 먼저 시도).
- 각 사용자 정보로 SSH 접속 시도.
- 접속 성공하면 해당 사용자 정보를 반환.
- 실패하면 다음 사용자 정보로 계속 시도.
- 모두 실패하면 None 반환.
SSH 를 시도하는 계정 정보는 settings 폴더 하위에 xxx.yaml 파일로 저장하면 됩니다.
SshManager 는 fabric 으로 로그를 가져 오기 전에 해당 호스트에 접속 가능한 계정 정보를 찾습니다.
이 때 yaml 파일에 등록된 계정 정보를 읽어서 사용합니다.
ssh.yaml
SSH:
- user_name: root
password: gAAAAABn9K2pfYmSQT0c4Ay4qenyD99ffiWxTQPDOtIa98j9H8WTZ0HpaXfXEvETFLP-Tz59UJVMMBIFw5LIjxBSjlCD4wSOLw==
- user_name: vagrant
password: gAAAAABn9K2pfYmSQT0c4Ay4qenyD99ffiWxTQPDOtIa98j9H8WTZ0HpaXfXEvETFLP-Tz59UJVMMBIFw5LIjxBSjlCD4wSOLw==
위 YAML 파일은 SSH 접속에 사용할 계정 정보 리스트를 담고 있습니다.
🧾 각 항목 설명:
| 필드 이름 | 설명 |
| SSH | 최상위 키로, SSH 관련 정보를 담는 리스트 |
| user_name | SSH 접속에 사용할 사용자명 (예: root, vagrant) |
| password | 암호화된 비밀번호 문자열 (Fernet 로 암호화) |
encoding_util.py
from cryptography.fernet import Fernet
from lib.models.constants.config_key import LDAP_KEY
def decrypt_cipher_text(ciphered_text):
cipher_suite = Fernet(LDAP_KEY)
try:
result = str((cipher_suite.decrypt(ciphered_text.encode())), 'utf-8')
except Exception as e:
result = None
print(f"An error occurred: {e}")
return result
def encrypt_cipher_text(text):
cipher_suite = Fernet(LDAP_KEY)
try:
result = str(cipher_suite.encrypt(text.encode()).decode())
except Exception as e:
result = None
print(f"An error occurred: {e}")
return result이 코드는 cryptography 라이브러리의 Fernet 모듈을 이용하여 문자열을 암호화/복호화하는 유틸리티 함수들을 정의하고 있습니다. 주로 비밀번호, API 키, 인증 정보 같은 민감한 데이터를 안전하게 처리하기 위해 사용됩니다.
🔐 핵심 개념 요약
- Fernet은 대칭키(하나의 키) 기반 암호화 방식입니다.
- LDAP_KEY는 암호화와 복호화에 사용되는 비밀 키입니다.
- 암호화된 문자열은 일반적으로 gAAAAA... 형태로 시작합니다.
📌 요약
| 함수 이름 | 설명 |
| encrypt_cipher_text | 평문을 Fernet으로 암호화 |
| decrypt_cipher_text | 암호화된 문자열을 복호화 |
| LDAP_KEY | 암호화/복호화에 사용되는 비밀 키 |
2) LogSearchScheduler
주어진 조건에 따라 로그 검색 단계를 스케줄링하고 연결 정보를 준비하는 로직을 담고 있습니다. 이 클래스는 BaseLogSearchScheduler라는 부모 클래스를 상속받아 동작합니다.
📌 정리
| 항목 | 설명 |
| LogSearchScheduler | 로그 검색 단계별 작업을 스케줄링하는 클래스 |
| get_step_connect_infos | 주어진 단계에 맞는 SSH 등 연결 정보 설정 |
| schedule_steps | 서비스 유형에 따라 로그 검색 단계를 설정 |
| 사용 예 | 멀티 스텝 로그 분석 (예: Gateway → API → Echo 순으로 연결 확인 및 로그 추출) |
다음은 로그 검색 스케줄링 시스템의 베이스 클래스, BaseLogSearchScheduler의 정의입니다.
base_log_search_scheduler.py
from lib.models.constants.const_response import RespStatus, RespMessage
from lib.models.log.respone.log_search_response import LogSearchResponse
from lib.util.config_util import load_service_connect_infos_from_yaml, load_ssh_user_infos_from_yaml
class BaseLogSearchScheduler:
def __init__(self, manager, yaml_loader, config_loader):
self.manager = manager
self.yaml_loader = yaml_loader
self.config_loader = config_loader
self.env = manager.env
self.keyword = manager.keyword
self.service_name = manager.service_name
self.level = manager.level
self.logs = None
self.index = 0
self.total = 0
# 전체 main steps
self.all_main_steps = []
# 현재 main step
self.current_main_step = None
# 전체 sub steps
self.all_sub_steps = None
# 현재 sub step
self.current_sub_step = None
self.step_connect_infos = None
self.all_connect_infos = self.get_all_connect_infos()
self.env_connect_infos = self.get_env_connect_infos()
self.ssh_connect_infos = self.get_ssh_connect_infos()
def get_all_connect_infos(self):
if self.env is None:
return None
return load_service_connect_infos_from_yaml(self.yaml_loader)
def get_env_connect_infos(self):
env_connect_infos = []
for item in self.all_connect_infos:
if item.env.upper() != self.env.upper():
continue
env_connect_infos.append(item)
return env_connect_infos
def exist_main_step(self):
if self.all_main_steps:
return True
else:
return False
def exist_sub_step(self):
if self.all_sub_steps:
return True
else:
return False
# log search step 을 리턴함
def get_current_main_step(self):
return self.current_main_step
# sub steps 를 스케줄링
def schedule_sub_steps(self):
print("schedule_sub_steps")
def get_next_main_step(self):
if not self.all_main_steps:
return None
self.current_main_step = self.all_main_steps.pop(0)
return self.current_main_step
def get_all_sub_steps(self):
return self.all_sub_steps
def get_next_sub_step(self):
if not self.all_sub_steps:
return None
self.current_sub_step = self.all_sub_steps.pop(0)
return self.current_sub_step
# log search step 을 리턴함
def get_step_connect_infos(self, step):
return self.step_connect_infos
def ensure_step_connect_info(self):
print("")
def get_step_log_path(self, step):
return self.step_log_path
def get_ssh_connect_infos(self):
return load_ssh_user_infos_from_yaml(self.yaml_loader)
def setLogs(self, logs):
self.logs = logs
def get_failed_response(self, message):
response = LogSearchResponse()
response.command_type = "log"
response.status = RespStatus.FAILED.value
response.message = message
response.index = self.index
response.total = self.total
return response
def get_success_response(self):
response = LogSearchResponse()
response.command_type = "log"
response.status = RespStatus.SUCCESS.value
response.message = RespMessage.SUCCESS.value
response.index = self.index
response.total = self.total
return response
def get_connect_infos_by_service_name(self, service_name):
connect_infos = []
for item in self.env_connect_infos:
if item.service.service_name != service_name:
continue
connect_infos.append(item)
return connect_infos
여러 서버 환경 및 서비스 구성 정보를 바탕으로 로그 검색 단계를 스케줄링하고, 연결 정보를 관리하는 핵심 역할을 합니다.
📦 주요 기능 정리
| 설명 | |
| 환경 설정 로딩 | YAML에서 서비스 및 SSH 연결 정보 로드 |
| 단계 관리 | 로그 검색 단계(main/sub step) 관리 |
| 연결 정보 제공 | 특정 서비스/환경에 맞는 SSH 및 서비스 연결 정보 반환 |
| 응답 생성 | 성공/실패 응답(LogSearchResponse) 생성 |
3) LogParser
로그 파싱은 정규식을 사용합니다.
이 코드는 로그 분석이나 정규식 기반의 파싱 시스템에서 정규표현식 패턴을 정의하는 상수 집합입니다. RegPattern 클래스는 다양한 로그 항목을 추출하기 위해 사용되는 파라미터화된 정규표현식 템플릿을 제공합니다. 즉, 특정 필드명을 지정하면 그것에 맞는 정규식을 생성할 수 있도록 설계되어 있습니다.
reg_pattern.py
from lib.models.log.log_pattern import LogPattern
class RegPattern:
WORD = r'(?P<%s>\S+)'
B_WORD = r'\[(?P<%s>\S+)\]'
B_WORD_AST = r'\[(?P<%s>\S*)\]'
TIME_RECEIVED = r'\[(?P<%s>[\w:/]+\s[+\-]\d{4})\]'
TIMESTAMP = r'(?P<%s>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2},\d{1,3})'
REQUEST_FIRST_LINE = r'"(?P<%s>(\S+) (\S+)\s*(\S+)\s*)"'
STATUS = r'(?P<%s>\d{3})'
USER_AGENT = r'"(?P<%s>(\S+)\s*(\S+))"'
DQ_WORD = r'"(?P<%s>\S+)"'
DIGIT_MS = r'(?P<%s>\d{1,}ms)'
LEVEL = r'(?P<%s>(INFO|ERROR|WARN|TRACE|DEBUG|FATAL))'
B_TRACE_SPAN_PARENT_ID = r'\[(?P<%s>[A-Za-z0-9]*,[A-Za-z0-9]*,[A-Za-z0-9]*)\]'
ANY = r'(?P<%s>.*)'
RESOURCE = r'resource=(?P<%s>\d{1,5}),'
STATUS_CODE = r'"status_code":"(?P<%s>[A-Za-z0-9]*)"'
REQUEST_ID = r'"request_id":"(?P<%s>[A-Za-z0-9]*)"'
SPACE = LogPattern(r'\s', None)
SPACE_MORE = LogPattern(r'\s+', None)
COLON = LogPattern(r':', None)
HYPHEN = LogPattern(r'-', None)🔍 구조 설명
📦 클래스: RegPattern
이 클래스는 모두 클래스 변수(class-level constant)로 정의되어 있으며, 로그 문자열을 파싱하기 위해 활용됩니다.
📌 주요 패턴 설명
| 변수명 | 설명 | 정규표현식 | 비고 |
| WORD | 공백 없는 단어 | (?P<%s>\S+) | 그룹 이름 지정 가능 |
| B_WORD | 대괄호로 둘러싸인 단어 | \[(?P<%s>\S+)\] | 예: [INFO] |
| B_WORD_AST | 빈 문자열도 허용 | \[(?P<%s>\S*)\] | 빈 문자열도 가능 |
| TIME_RECEIVED | Apache 로그 시간 | \[(?P<%s>[\w:/]+\s[+\-]\d{4})\] | 예: [10/Oct/2000:13:55:36 -0700] |
| TIMESTAMP | 일반적인 타임스탬프 | (?P<%s>\d{4}-\d{2}-\d{2} ... ) | 예: 2023-09-01 12:30:45,123 |
| REQUEST_FIRST_LINE | HTTP 요청 첫 줄 | "(?P<%s>(\S+) (\S+)\s*(\S+)\s*)" | 예: "GET /index.html HTTP/1.1" |
| STATUS | HTTP 상태 코드 | (?P<%s>\d{3}) | 예: 200, 404 |
| USER_AGENT | User-Agent 파싱 | "(?P<%s>(\S+)\s*(\S+))" | |
| DQ_WORD | 큰따옴표로 둘러싸인 단어 | "(?P<%s>\S+)" | |
| DIGIT_MS | ms 단위 시간 | (?P<%s>\d{1,}ms) | 예: 300ms |
| LEVEL | 로그 레벨 | `(?P<%s>(INFO | ERROR |
| B_TRACE_SPAN_PARENT_ID | Trace 정보 | \[(?P<%s>...) | 예: [abc123,def456,ghi789] |
| ANY | 아무 문자열 | (?P<%s>.*) | |
| RESOURCE | resource 정보 | resource=(?P<%s>\d{1,5}), | |
| STATUS_CODE | JSON 로그의 status_code | "status_code":"(?P<%s>[A-Za-z0-9]*)" | |
| REQUEST_ID | JSON 로그의 request_id | "request_id":"(?P<%s>[A-Za-z0-9]*)" |
4) 코드 실행
Vagrant 파일은 3.2편에서 만든 vagrant 파일을 사용했습니다.
아래와 같이 gateway01, api01, echo01 VM 은 실행 중이어야 합니다.

jbdesk.py 를 실행합니다.
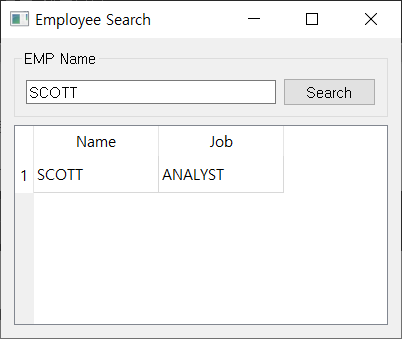
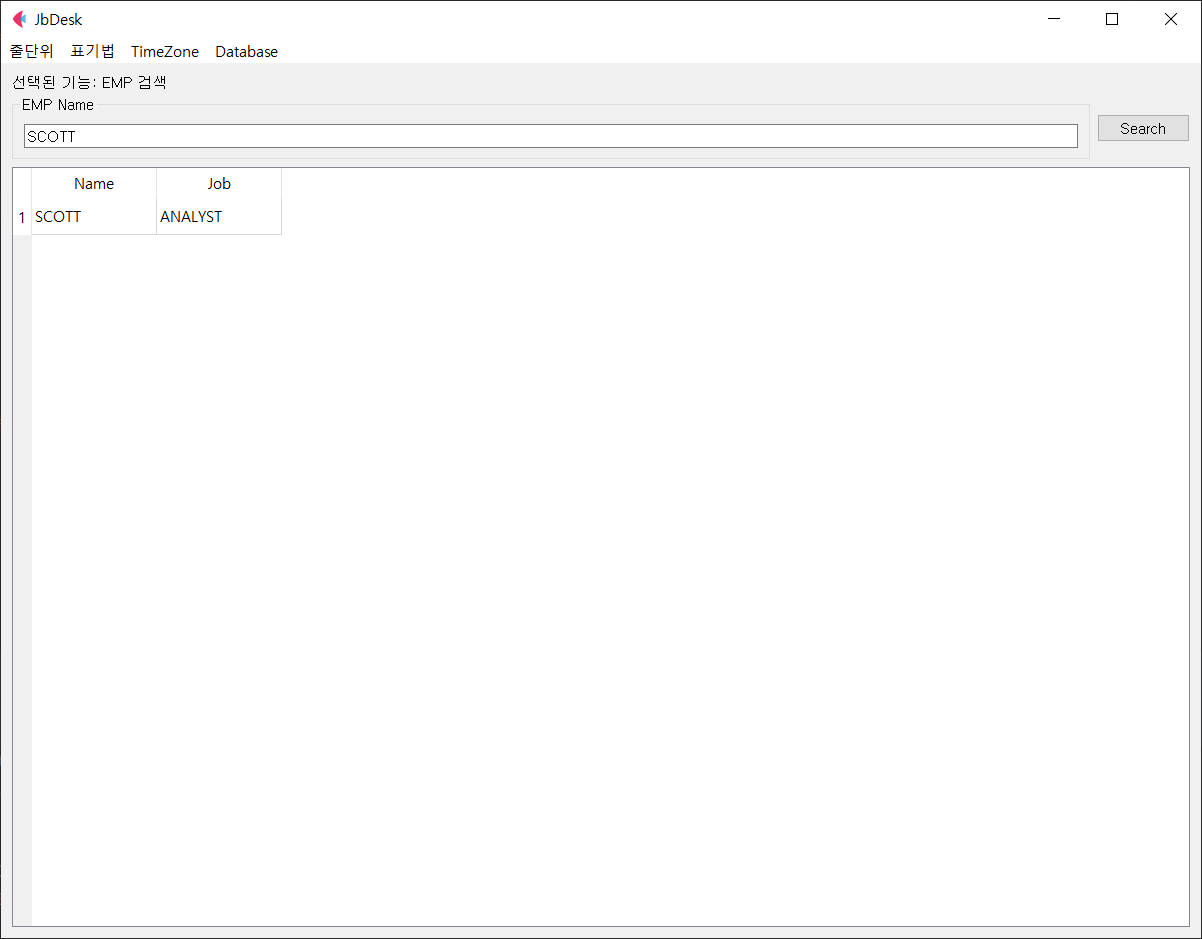
위 서버의 로그를 검색하기 위해서는 Tid 를 입력하고 Search 를 클릭하면 됩니다.

'유틸리티 > JbDesk' 카테고리의 다른 글
| JbDesk 3.2편-fabric 으로 로그 메시지 추적 (6) | 2025.04.08 |
|---|---|
| JbDesk 3.1편-Python fabric 으로 원격 커맨드 실행 (0) | 2025.04.08 |
| JbDesk 2.3편-Database 검색 (MariaDb + Multi-tenant) (1) | 2025.04.05 |
| JbDesk 2.2편-Database 검색 (Oracle + SQLAlchemy) (0) | 2025.04.03 |
| JbDesk 2.1편-Database 검색 (SQLite + SQLAlchemy) (0) | 2025.03.28 |